のリンクをクリックして,2003gaironディレクトリの中にダウンロード・保存する。
20101016gairon.tar.gz
いつものとおり,
% tar zxvf 20101016gairon.tar.gz
として解凍する。すると,
20101016gairon.txt
というファイルが存在する(下図:ウィンドウの形式が違うが気にしないこと)。
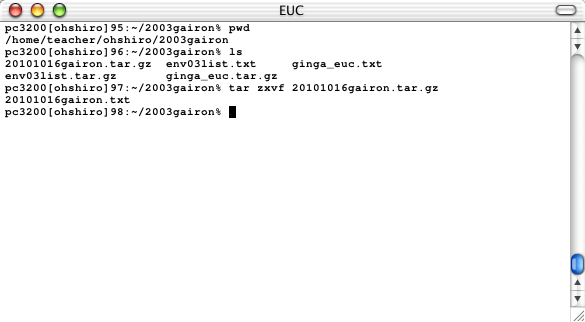 |
このファイルの内容を表示すると,次図のようになっている。このファイルは,2010年のある授業の出席
調査ファイルである。各実習マシンと,その実習マシンにログインしている学生のIDが掲載されている。この
ファイルを使って,grepを試してみよう。
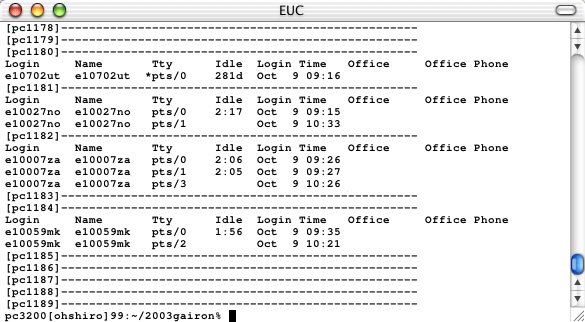 |
% grep "正規表現" ファイル名
これで,指定したファイルの中から,指定した正規表現にマッチする文字列を含む行が表示される。
ためしに,ohshiroを検索してみよう。
% grep "ohshiro" 20101016gairon.txt
と実行してみると,"ohshiro"を含む行が表示される(下図)。
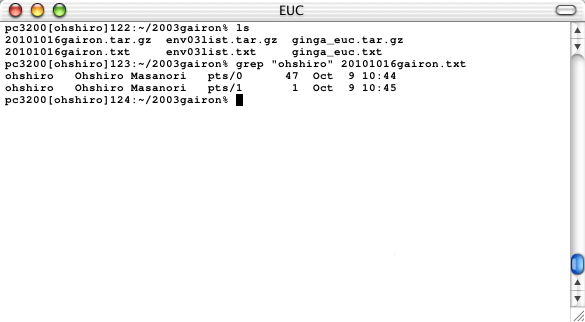 |
同様に,学生用IDを含む行だけを表示してみよう。学生(他学科含む)のIDは,正規表現では
[ecsm][0-9][0-9][0-9][0-9][0-9][a-z][a-z]
で表現できるので,
% grep "[ecsm][0-9][0-9][0-9][0-9][0-9][a-z][a-z]" 20101016gairon.txt
とすれば良い(下図)。
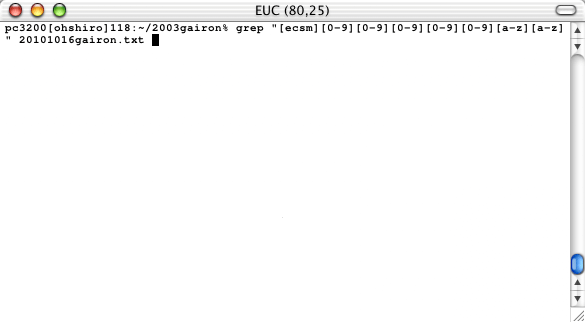 |
実行結果は,次図のようになる。ちゃんと学生のIDを含む行だけが表示されているのが分かる。
 |
問題:grepを使って,20101016gairon.txtから,名字のイニシャルがkの人のIDが載っている行だけを表示せよ。