●次はhello2.cpp
次にこのList 1.1と同じ機能を,よりC++らしく書き換えた例をList 1.2(hello2.cpp)に示します。

C++でコンパイル・実行すると,結果がList 1.1のときと同一であるのがわかります。
なお,このままでは Visual Studio のコンソールアプリケーションとして実行した場合にウィンドウが
すぐ閉じてしまいます。それを防ぐには,下図赤字の様にキーボードからの入力を待つ処理を2行分加えて下さい。
この処理を加えると,プログラム終了後に改行キーを押すとコンソールウィンドウが閉じるようになります。

ではList 1.1とList 1.2を比べながら,C++独自の特徴をいくつか紹介することにします。
・<iostream>
1行目,List 1.1では標準Cライブラリから受け継いだ標準入出力モジュールのヘッダファイル<stdio.h>
をインクルードしていましたが,List 1.2では,そのかわりに<iostream> というヘッダファイルを
インクルードしています。
そう,この<iostream>こそが,C++の機能を活かした新しい標準入出力モジュールのヘッダファイルなの
です。このように,ANSI/ISO C++固有の標準ライブラリヘッダには,拡張子がつきません。
なお,“iostream”は“Input Ousput Stream”の略です。データのファイルへの出力やファイルから入力,
画面への出力やキーボードからの入力などの様にデータがプログラムの内部と外部との間を往き来する際
に通る“道”はストリーム(stream)と呼ばれます。streamとは“流れ”・“小川”などという意味で,データが
流れて出入りする様子を表しています。そして,C++でも同様にデータの入出力対象はストリームと呼ば
れるのです。
・using namespace std;
3行目には見慣れない
using namespace std;
という行がありますが,今は無視して下さい。後ほど説明します。
・
cout
List 1.1において,標準入出力関数printf()を使って文字列を出力していた行に相当するのが,List 1.2の
7行目です。つまり,この行のために<iostream>をインクルードしたわけです。
List 1.2再掲
この行の式を見てみると大きく4つの要素に分けることができます。つまり,一番左にあるcout,文字列,endl,
そしてこれらを結んでいる<<演算子です。
では,左の方から見ていきましょう。
まずcoutですが,これはいったい何なのでしょう? 標準C言語
ライブラリには,標準の出力用ストリームとしてstdoutが用意されていて,これは画面などを出力対象に
したストリームでした。例えば,printf()関数は出力先を標準出力ストリームstdoutとする書式つき出力関数
です。書式つき出力関数fprintf()は,第1引数に出力先を指定でき,
fprintf( stdout, 書式文字列, … );
は
printf( 書式文字列, … );
と同じ意味でした。
実はcoutは,標準Cライブラリのstdoutに相当するC++の標準出力ストリームなのです。同様に,C言語の
標準入力ストリームstdinに相当するC++の標準入力ストリームとしてcinがあります。
・<<演算子
その右に来るのは,左シフト演算子<<です。シフト演算子<< と >> は,ビットの並びを指定された桁数
だけ横にずらす演算子です。以下に例を示します。
shift_operator.cpp
#include <stdlib.h> // 標準のsize_t型, strtol()関数, 非標準の_ltoa()_s関数を使うためにインクルード
#include <stdio.h>
int main( ) {
printf( "size of int : %lu\n", sizeof( int ) );
const char * vstr = "00001111";
char rs[20] = { 0 }; // 最初の要素を0に初期化してこの配列を空文字列として初期化する
int v = strtol( vstr, NULL, 2); // strtol( n進数表記文字列, NULL, n) は、n進数表記文字列をint型の値へ変換する標準関数
_ltoa_s( v, rs, 2); // _ltoa_s(整数値, 文字配列, n)は、整数値のn進表記文字列を指定した文字配列に格納する非標準関数
printf( "%032s", rs ); printf( " : オリジナルの値, 10進数では%d\n", v );
_ltoa_s(v << 1, rs, 2); // 1ビット左シフト
printf( "%032s", rs ); printf( " : 1ビット左シフト, 10進数では%d\n", v << 1 );
_ltoa_s(v << 2, rs, 2); // 2ビット左シフト
printf( "%032s", rs ); printf( " : 2ビット左シフト, 10進数では%d\n", v << 2 );
_ltoa_s(v >> 1, rs, 2); // 1ビット右シフト
printf( "%032s", rs ); printf( " : 1ビット右シフト, 10進数では%d\n", v >> 1 );
getchar( );
return 0;
}
実行結果
このように, 整数値<<整数値, 整数値>>整数値 というように使い,左の整数値のビットの並びを,右の
整数値で指定された桁数だけずらします。
ここで,皆さんはきっと強い疑問を持つことでしょう。「一体どうして,こんなところにシフト演算子がくる
のだろう。シフト演算子の左側には,シフトされる整数型オペランド,右にはシフトビット数を示す整数型
オペランドがくるはずなのに。なんで,左オペランドに出力ストリームがきて,右オペランドに文字列が来る
んだ??」という具合に。
整理すると,
(a) 整数型 << 整数型
となっているべきところが,List 1.2では
(b) 出力ストリーム << 文字列
となっているわけです。そしてこの式は,左オペランドの出力ストリーム(List 1.2ではcout)へ右オペランドの
文字列を出力しているようです。
この答えは,C++の機能の一端を示しています。タネを明かすと,C++では,既存の演算子に別の意味を持た
せることが可能なのです。
詳しくはまだ触れませんが,C++における演算子は,関数として定義することができ,また,同じ名前の関数
に別の意味を持たせることが可能なのです。関数としての演算子を演算子関数(operator function)と呼び,
同じ名前の関数に別の定義を持たせることを関数の多重定義(オーバロード, overload)と呼びます。
要するに,(a)と(b)の<<演算子は,“<<”という見かけは同じでも中身は異なる関数というわけです。(a),(b)
の<<演算子を関数として記述してみましょう。
左オペランドを第1引数,右オペランドを第2引数とすれば,その仕様の概要はそれぞれ次のようになります。
(a')
第1引数:整数型
第2引数:整数型
機 能:第1引数を第2引数で指定さ
れたビット数だけ左へシフト
返却値 :シフトされた第1引数
(b')
第1引数:出力ストリーム
第2引数:文字列
機 能:第1引数の出力ストリーム
へ第2引数の文字列を出力
返却値 :第1引数の出力ストリーム
こうしてみると,(a')と(b')では引数の型が異なっていることがわかりますね。どうやって「複数の定義を持つ
ひとつの関数名」から,正しい定義が選ばれるのか。その答えがここにあります。つまり,ある関数名が式の中
に現れたとき,いくつもある定義の中から仮引数の型情報と実引数の型情報が一致する関数定義だけが,自動的
に呼び出されるのです。
第1引数(=左オペランド)に出力ストリームを持つ<<演算子は,右オペランドの種類によって様々なバリエー
ションが定義されています。例えば,
(c) 出力ストリーム << double型
というオペランドを持つ<<演算子は,
(c')
第1引数:出力ストリーム
第2引数:double型
機 能:第1引数の出力ストリーム
へ第2引数のdouble型数値
を文字列に変換して出力
返却値 :第1引数の出力ストリーム
というように定義されているのです。数値型・文字型・文字列型・ポインタ型など,C++言語に組み込まれている
基本的な型は,このように多重定義された<<演算子によって,適切な文字列に変換されて,指定されたストリーム
に出力されるようになっています。
ですから
cout << 1.0;
とすると,これは実数値1.0を文字列に変換して
1.0
と標準出力ストリームに出力する,という内容になります。
<<演算子は左結合(左から結合していく)の演算子なので,結合の仕方はFig. 1.2-(1)のようになります。
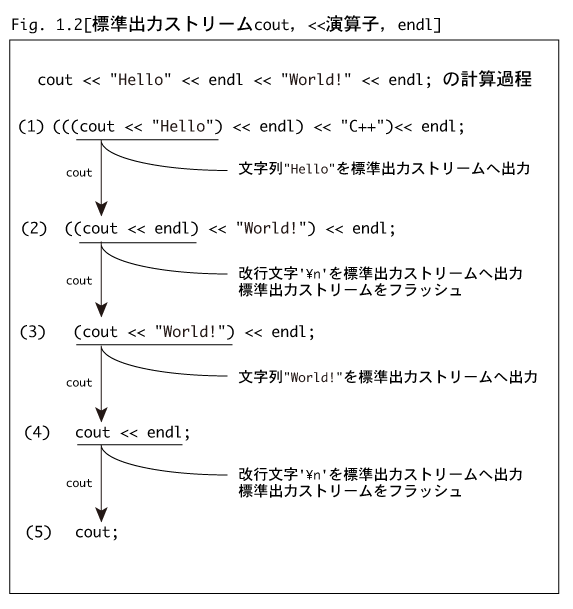
最初に
(cout << "Hello")
が実行され,文字列"hello"が表示され,返却値coutがこの部分式と置き換わり,全体の式はFig. 1.2-(2)となって,
次に
(cout << endl)
が実行される番になります。さて,このendlは何なのでしょう?
・endl
List 1.1およびList 1.2とそれらの実行結果を比べて見た方なら察しがついたと思いますが,このendlを<<演算子
で出力ストリームにほおりこむと,改行文字'\n'が出力されるのです。つまり,効果の面では
cout << endl;
はANSI Cで記述した
printf( "%c", '\n' );
に等しいと言えます。では,endlは文字定数'\n'なのでしょうか。実は,endlは関数名なのです。標準C言語および
C++では,関数名をただ書けば,それはその関数へのポインタとして扱われます。
関数ポインタとは,文字通り,メモリ上に読み込まれている関数の実行コードを指し示すポインタです。
関数ポインタから,間接的に関数を呼び出すことが可能です。如何に例をあげます。
#include <stdio.h>
// 2個のint型仮引数を持ちint型の値を返す関数の型名として、myfunctype を定義する。
typedef int myfunctype( int a, int b );
int add( int a, int b ) { return a + b; }
int sub( int a, int b ) { return a - b; }
int main( ) {
// myfunctype型の関数ポインタ変数 fp を宣言し、関数add( )へのポインタを初期値とする。
myfunctype * fp = add; // 関数名はそのままその関数へのポインタ値として扱われる。
printf( "%d\n", fp( 10, 2 ) ); // add( )関数が実行され、12と表示される。
// 今度は、関数ポインタ変数 fp に関数sub( )へのポインタを代入する。
fp = sub; // 関数名はそのままその関数へのポインタ値として扱われる。
printf("%d\n", fp(10, 2)); // sub( )関数が実行され、8と表示される。
getchar( );
return 0;
}
このように,
関数ポインタを使う場合は,
(1)
typedefで用途に合わせた関数型を定義し,
(2) (1)で定義した関数型を柄って関数ポインタ変数を宣言し,
(3) その関数ポインタ変数に,関数名が表している関数ポインタ値を代入(もしくは初期値として指定)する。
(4)
関数ポインタ変数を関数名のように使って,関数ポインタ値がさしている関数を呼び出す。
という流れが一般的です。
さて,話しを<<演算子に戻しましょう。つまり,ここでの<<演算子は,
(d) 出力ストリーム << 関数ポインタ
となっていて,このときに呼ばれる関数の定義は
(d')
第1引数:出力ストリーム
第2引数:関数ポインタ
機 能:第1引数の出力ストリーム
を第2引数で指定された関
数に渡して,その関数を実
行する
返却値 :第1引数の出力ストリーム
というものです。関数endl()は,<<演算子から呼ばれて,指定された出力ストリームに改行文字'\n'を書き込み,
その出力ストリームをフラッシュ(flush)します。
通常,出力装置はメモリに比べて出力に要する時間が長いので,ストリームへ出力する際は,一時的なメモリ領域
(バッファ, buffer)にデータをためてから,適宜,バッファの内容を出力装置に送り出すようになっています。
このように,ストリーム用のバッファの内容を出力装置に送り出すことをフラッシュと呼ぶのです。
フラッシュしなければ,出力したはずのデータが実際にはまだバッファ中にあって出力されていない,といった
ことがおこります。標準入出力ストリーム相手にデータの入出力を行うなら,こまめにフラッシュを行った方が
良いのは明らかです。
したがって,標準出力ストリームに改行文字'\n'を単独で
cout << '\n';
というように出力するよりは,endlを使ってこまめにフラッシュすることをおすすめします。
というわけで,式全体は順次,
(cout << "World!") << endl; (Fig. 1.2-(3))
cout << endl; (Fig. 1.2-(4))
cout; (Fig. 1.2-(5))
と評価されていき,標準出力ストリームに
Hello
World!
と表示されるというわけです。
・<<による出力の特徴
<<演算子を用いた出力の利点を簡単にまとめてみましょう。
■変換指定と値の並びを対応づける必要がない
C言語標準ライブラリのprintf()関数は便利ですが,第1引数の変換指定と,第2引数以降の引数の対応をきっちり
と対応づけなければなりません。変換指定と引数が正確に対応していないと,変換がうまくいかずにプログラムの動作
不良がおこります。誰もがこのような間違いをおかした経験があるはずです。<<演算子を使えば,今後そのようなこと
は起こらなくなります。また,気軽にデータをこの出力並びに挿入したり,外したりすることが可能になります。
■イメージしやすい
式全体を見ると,<<演算子の外見のおかげで,データが一番左側の出力ストリームに流れ出ていくといった印象を受けます。
■書式付きの出力も可能
実は,printf()関数のように書式付きの出力も可能です。しかし,今はまだ詳しくは触れません。入出力に関しては,後の章で詳しく解説します。
● 名前空間
さて,List 1.1でまだ説明していない部分がありました。
using namespace std;
というところです。これは,C++で導入された名前空間(name space)という機能に関連があります。ですから,まず
はこの名前空間について解説しましょう。
Level 0でも説明しましたが,関数の仮引数や{}ブロック内で宣言された変数などの識別子の有効範囲は,そのブロック
の中だけでした(ブロックスコープ)。もし関数を定義するときに,別の関数で宣言されている変数名が使用できないとしたら,
いちいち全ての関数の変数を調べなくてはならなくなります。
関数内で宣言した識別子がブロックスコープを持っているおかげで,関数を定義するときに,自由に変数などの名前が
つけられるわけです。
一方,グローバルなスコープを持つ識別子はどうでしょう。
例えば,関数名です。C言語では,グローバルな識別子は単一のグローバルなスコープの中にごった煮状態で定義されます
。
つまり,グローバルスコープでは常に名前の衝突が起こり得るのです。
グローバル識別子の総数が少ないなら,その全てに目を通して,既存の識別子と同一の名前を付けないように気を配り続ける
こともできるでしょう。しかし,巨大なライブラリを利用する時にはどうでしょうか。膨大な数にのぼる識別子を全てチェック
して,名前の衝突を回避することができるでしょうか。おそらく答えはNOでしょう。この問題を解決する妙案はないもの
でしょうか。
・名前空間の定義
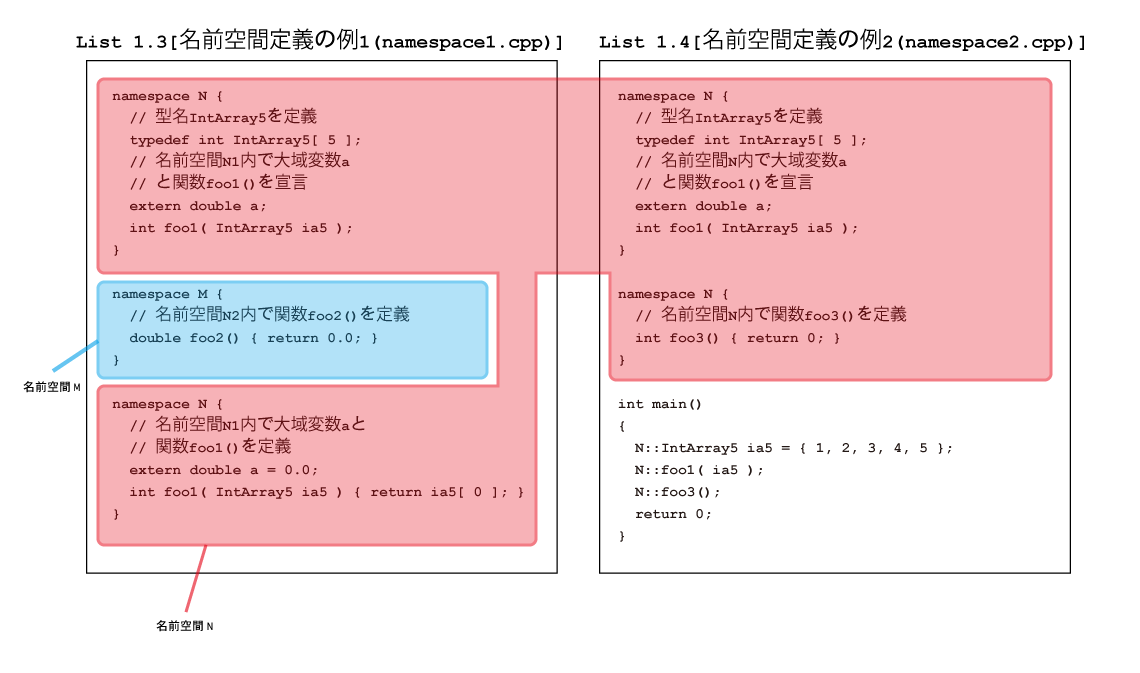
この問題を解決してくれるのが,名前空間定義機能なのです(Fig. 1.3)。一言で言えば,“グローバルスコープを分割する
ために,名前付きブロックスコープを提供する”,ということになるでしょう。

Fig. 1.3-(1)に示すように,名前空間を定義する構文は次のようになっています。
namespace N { }
このブロックの中で宣言された識別子は,全て名前空間Nというスコープの中に属することになります。このような名前空
間定義は,グローバルな位置(つまり関数定義の外側部分)でならどこでも可能です。
例えば,List 1.3では,NとMの2つの名前空間を定義しています。名前空間の名称が同じなら,離れたところでも同じ
名前空間を定義したことになるので,関数foo1()は,宣言・定義ともに名前空間Nに属することになるわけです。
さらにソースファイルが別でも,同じ名前の名前空間どうしは同一の名前空間として扱われます。
ですから,List 1.4の関数foo3()もList 1.3の関数foo1()と同じ名前空間Nに属することになります。このように名前空間
を使えば,ファイルにまたがった論理的なスコープ(しかも名前つき)を導入できるわけです。単一のグローバルなスコープ
と物理的なファイルスコープの制約を受けていたC言語のシステムに比べると,これは飛躍的な進歩であると言えます。
・名前空間内の識別子の参照
では,特定の名前空間に属した識別子を使うときはどうすればいいのでしょう。そのためには,C言語には無かった
有効範囲決定(scope resolution)演算子:: を使います(Fig. 1.3-(2))。
具体的には,
名前空間名::識別子
という具合にします。List 1.3の例では,名前空間Nの中の関数foo1()を呼び出すには,
N::foo1();
と指定することになります。なお,同じ名前空間の中では::演算子を使わず,識別子だけで直接参照することができます。
しかし,一回一回の呼び出しごとに“N::”を付けなければならないのは,めんどうです。そこで,一番始めの呼び出し
の前にあらかじめ
using 名前空間名::識別子;
と宣言しておけば,あとは識別子だけで“名前空間の名称::識別子”全体をさしたことになります。これを,名前空間利用宣言
(name space using declaration)と呼びます(Fig.1.3-(3))。
この宣言自体の有効範囲は,この宣言の地点からこの宣言が行われたスコープの終わりまでです。List 1.3の関数foo1()の
例だと,
using N::foo1;
と宣言しておくだけで,foo1();と呼べば,N::foo1()を呼んだことになります。
これで,かなり便利にはなりますが,識別子の数が多い場合には,名前空間利用宣言を多くの識別子に対して行わなくて
はなりませんから,これもなかなかに大変です。そこで,特定の名前空間内の全識別子を利用可能にする命令があります。
それを名前空間利用指令(name space using directive)といい(Fig. 1.3-(4)),構文は次のようになっています。
using namespace 名前空間名;
この命令を使うことで,指定した名前空間の全ての識別子を,“名前空間名::”無しで使えるようになります。この命令自体
の有効範囲は,この命令の地点からこの命令が行われたスコープの終わりまでです。
この命令は便利なのですが,乱用すると名前空間を導入した意味が無くなってしまいますので注意が必要です。
特定の名前空間の中にモジュールやライブラリを作成することで,他の大域スコープを持つ名前との衝突を心配せずに
ライブラリを作成することができるわけです。また,様々な会社の作成したライブラリを組み合わせても,名前の衝突が
あまりおこらなくなります。ただし,あまりに短い名前空間名が用いられると,他のライブラリが同じ空間名を持つ可能性
が高くなってしまうことには注意が必要です。名前空間名は,適度な長さを持ち,意味が明確なものをつけるようにしまし
ょう。
・名前無し名前空間
ところで,名前空間を定義するときに,名前空間名を省略すると,それは名前無し名前空間(unnamed namespace)
というものを定義することになります(Fig. 1.4-(1))。

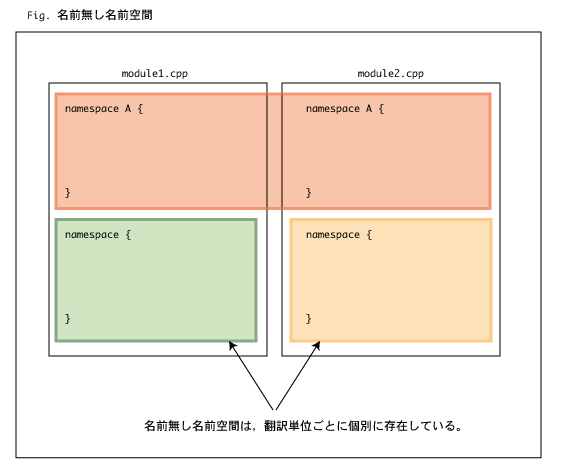
名前無し名前空間の中で宣言・定義された識別子は,この名前無し空間定義のある翻訳単位内からはそのまま識別子名
だけで参照できますが,他の翻訳単位からは参照できません。
また,各翻訳単位内で定義された名前無し名前空間は別の名前空間として扱われます。ですから,この名前無し名前空間
は翻訳単位の外部から識別子を隠すのに利用できます。そういう意味では,saticつきでグローバルな識別子を宣言・定義
するのと似ています。
実は,C++では名前が翻訳単位内に局所的であることを示すのに,予約語staticを用いるのは推奨されていません。
本来,名前空間は大域の各識別子の役割を明確にするために導入されたわけで,全ての大域識別子はいずれかの名前空間内
で宣言・定義するのが理想的です。ですから,staticつきで大域識別子の宣言・定義を行うより名前無し名前空間を用いる
べきです。
・名前空間の別名定義
名前空間の名前には別の名前がつけられます(Fig. 1.4-(2))。この別名定義を使えば,あまりに長い名前空間名に適度に
短い別名を与えることができますし,バージョンが異なる複数のライブラリを切り替えながら使用するなどの用途が考え
られます。Fig. 1.4-(2)の例にあげたコードは,古いバージョンのライブラリ(名前空間MyLibVersion01内に定義)と新しい
バージョンのライブラリ(名前空間MyLibVersion02内に定義)を同一の名前空間名MyLibで使用する例です。古いバージョ
ンのライブラリを使用するときには,別名定義を
namespace MyLib = MyLibVersion01;
とし,新しいバージョンを使用するときには
namespace MyLib = MyLibVersion02;
とすればよいわけです。
・名前空間名の識別子の定義
名前空間で宣言された識別子は名前空間のブロックの外でも,“名前空間::識別子名”という名前を使って定義を与えること
ができます。名前空間ブロックの外で定義を行う場合,該当する名前空間で既に宣言されている識別子でないとエラーになり
ます(Fig. 1.4-(3))。名前空間ブロックの中で定義を行う場合,その名前空間に入れるつもりのない識別子の定義をうっかり,
その中でやってしまうというミスが起こりえますが,ブロックの外で定義するようにすれば,そういった誤りを防ぐことが
できるというわけです。
・名前空間の合成
Fig. 1.4-(4)に示すように,名前空間利用指令をうまく使うと複数の名前空間をひとつの名前空間に合成することができます。
細かいモジュールごとに分割されていて,各モジュールに別々の名前空間が割り当てられているとき,それらをひとつの名前空間
を持つ大きなライブラリに統合する場合などに,この名前空間の合成手法は有用です。
・標準ライブラリの名前空間std
さて,これでList 1.2の3行目
using namespace std;
が何をやっているか理解できたでしょう。これは,名前空間stdの識別子を“std::”という装飾無しで利用する,という名前空間
利用指令なのです。では,stdとは? 実はC++のライブラリの識別子は,全てこの名前空間stdの中で宣言・定義されている
のです。つまり,coutもendlも本来は
std::cout
とか
std::endl
と書かれるべきなのです。前述したとおり名前空間利用指令の乱用はよくないのですが,いちいち全ての標準ライブラリの識別子
に“std::”をつけるとソースコードの1行あたりの文字数が非常に多くなってしまいますので,本資料ではスペースの都合上
,using namespace std;という記述を多用することとします。
○1.1.4 CヘッダとC++ヘッダ
ところで,C++の規格がC言語とできるだけ互換をとるように設計されていることは前述したとおりです。ですから,List 1.1
がそのままコンパイルできたことからもわかるとおり,C言語の標準ライブラリもC++の標準ライブラリの一部となっています。
つまり,stdio.hのような標準ヘッダもC++の標準ライブラリに用意されています。
さて,ここで名前空間についての問題が起こってきます。それは,C言語標準ライブラリの識別子名も名前空間stdの中に入れる
べき
か否か,ということです。C++の新しいポリシーに基づけば,標準ライブラリの識別子は全て名前空間stdの中で宣言・定義
されるべきです。しかし,それでは過去のC言語プログラムのソースコードをC++コンパイラで処理するためには,大幅に書き直
さなくてはならなくなるでしょう。
この問題を解決するために,C++標準ライブラリではC言語標準ライブラリを2種類用意しています。ひとつは,名前空間を指定
せずに識別子を参照できるもの,もうひとつは識別子を全て名前空間“std”の中で宣言・定義したものです。
前者を使用する場合には,C言語標準ライブラリと全く同名のヘッダファイルを用います。標準入出力モジュールのヘッダなら
おなじみのstdio.hです。後者を利用する場合にインクルードするヘッダは,対応するC言語標準ヘッダの名前の先頭に小文字の“c”
をつけて,さらに拡張子“.h”を省いたものになります。つまり,stdio.hに対応するヘッダは
cstdio
となります。この工夫によって,過去のC言語プログラムは大きな変更もなくC++処理系の下でもC言語標準ライブラリを使用でき
るわけです。一方,C++プログラミングでC言語標準ライブラリをどうしても使いたい場合は,cstdioなどの新しいヘッダをインクルード
して,名前空間stdの中にある識別子を
std::printf();
というように使わなくてはなりません。C言語と同じ拡張子“.h”つきの古いヘッダは“Cヘッダ”,iostreamやcstdioなどのC++固有
のヘッダは“C++ヘッダ”と呼ばれます。
使い分けの例を下図に示します。

