正当な操作は明確にわかっています(Fig. 2.3の例では操作A,B,C)。
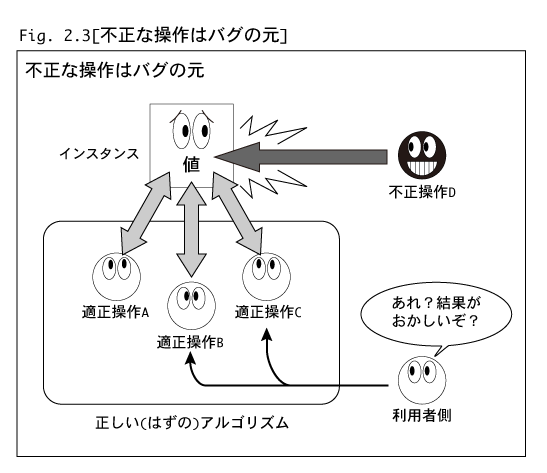
したがって,
・アルゴリズムの中心となるデータ
・そのデータへの正当な操作群
をまとめてひとセットとし,その他のいかなる処理からも該当データを見えないようにすれば,問題を解決することができそうです。C++には情報とそれに関連する
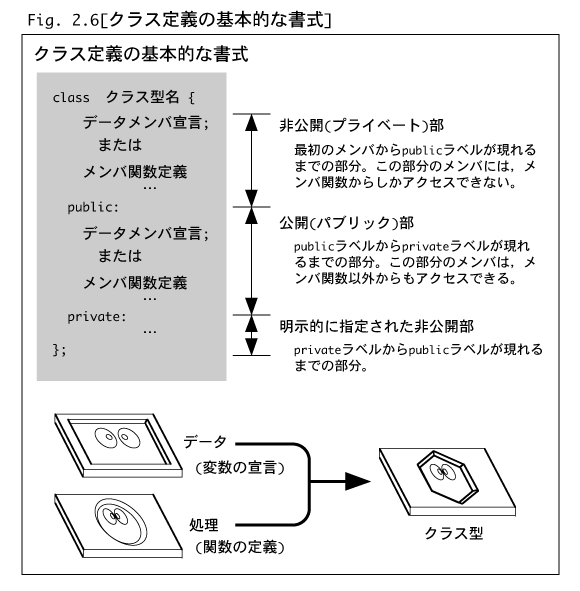
操作を組にするために,構造体型の概念を拡張したクラス型(class type)が用意されています。Fig. 2.6にクラス型の記述の仕方を示します。一見すると,
C言語の構造体とそっくりです。違いといえば,予約語structのかわりに新しい予約語classが使われているだけのような印象を受けます。
しかし,このクラス型にこそC言語からC++への大きな飛躍の仕組みが隠されているのです。
まず,クラス型がC言語の構造体と明らかに違うのは,メンバとして関数の定義を含めることが可能であることです。クラスのメンバとして定義された関数を
メンバ関数(member function)と呼びます(Javaで言うところのメソッド)。対して,データ部分をデータメンバ(data member)といいます。クラス型変数a
のメンバ関数f()を呼び出すときには,データメンバと同じく
a.f()
とすればよく,aへのポインタapからは
ap->f()
とすればメンバ関数f()を呼び出せます。
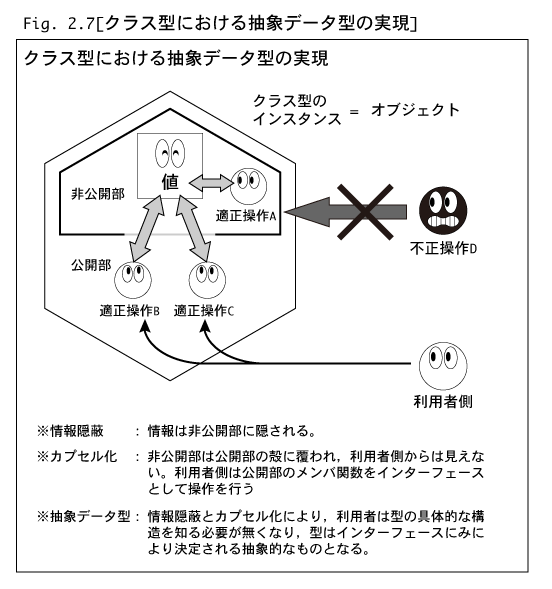
また,クラスの内部(メンバ宣言部)は,非公開(プライベート)部と公開(パブリック)部に分割されています。この各部分の区切りはprivateとpublicという特別
なラベルによって指定することができます。privateラベルからpublicラベルまでの間が非公開部で,publicラベルからprivateラベルまでの間が公開部です。
これらのラベルは,どのような順番で現れても構いません。また,最初のメンバからpublicラベルが現れるまでの部分は自動的に非公開部となります。なぜ,この
ように部分わけしたかというと,不正な操作によってデータメンバの値が参照されたり変更されることを防ぐためなのです。非公開部のデータメンバおよびメンバ
関数の名前には,メンバ関数の中からしかアクセスすることができないようになっているのです。一方,公開部のメンバは外部からも自由にアクセスすることが
できます。
例をList 2.6に示します。

List 2.6では,非公開データメンバのm1と,公開データメンバm2,公開メンバ関数のSetData()とPrint()を持つクラス型C1を定義
しています。メンバ関数の定義の中で,非公開メンバm2を参照している点に注目して下さい(10,14行目)。また,このリストを実行した後に30行目の//を省き
a.m1 = 0;
を有効にして,再度コンパイルしてみるとコンパイルエラーが発生するはずです。これは非公開メンバm1にアクセスしようとしてコンパイラに拒否されるためです。
このクラス型を使って実際にプログラムを記述する場合は,アルゴリズムの中心となるデータについては非公開部に,外部から呼び出されるべきメンバ関数は
公開部に置くことになります。List 2.5の単純なスタックアルゴリズムを,クラス型を使ってC++風に書き直したのがList 2.7です。

List 2.7を実行すると正しく
keep
と表示されます。次に38行目の//を外して
s1.sp = 1;
を有効にし,再度コンパイルしてみてください。コンパイルエラーとなって,List 2.5にみられたような不正な操作を未然に防いでいることがわかります。