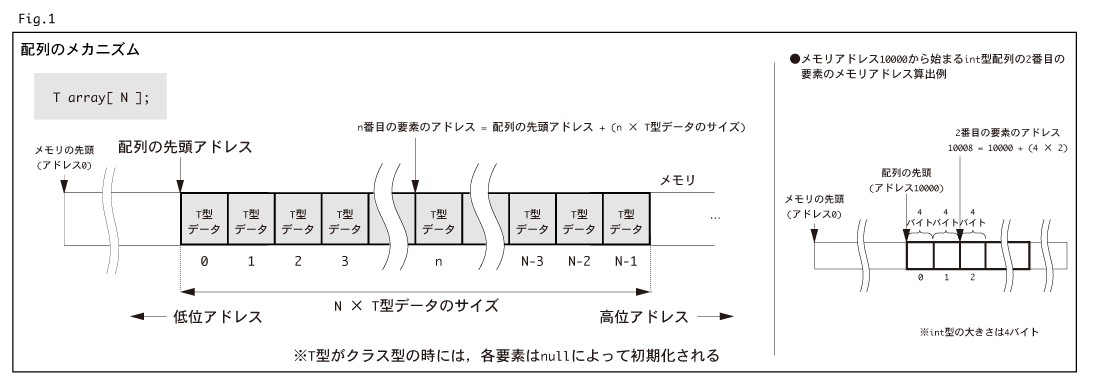
Fig.1が,N個のT型要素を持つ配列のメモリ上の姿です。T型のデータがちょうどN個分だけ格納できるひとかたまりのメモリ
領域が一度に確保され,そこに0番目から(N-1)番目の要素がすきまなく並んでいます。
プログラミング応用b 第9回『コレクション』 |
【情報の保持】
一般に,複数の情報を処理して有効な結果を得るためには,その複数の情報の全てをメモリ上に保持する必要があります。
まずは、情報の保持の最も基本的な方法である配列の復習と,その改良版であるベクタについて学習していきます。
【配列の復習】
複数の情報を保持するための最も簡単な手段は,皆さんもご存じの配列です。配列の使用例として,中世の手持ち武器の
ファイル weapon.csv から各武器のデータを読み込んで,逆順に表示する“逆順表示”プログラムを考えてみましょう。
ここでは“逆順に武器データを扱う”という処理を行うために,いったん全てのデータを配列に格納することにします。
List 1が配列を使ってweapon.csvの中身を逆順表示するJavaプログラムの簡単な例です。89個の武器データが入った
テキストファイル weapon.csv は、Eclipseで作成したプロジェクトフォルダ直下に置いて下さい。実行したら,weapon.csv
の中身が逆順に表示されているか確認しましょう。
List 1 Reverse2.java データファイル weapon.csv
import java.io.*;
public class Reverse2 {
public static void main( String args[] ) {
try {
final int arrayN = 89;
// 89個のString型オブジェクトを格納する配列
String[] buffers = new String[ arrayN ];
String str;
int i = 0;
BufferedReader br = new BufferedReader
( new FileReader( "weapon.csv" ) );
while( ( str = br.readLine() ) != null ) {
buffers[ i++ ] = str; // 配列にデータを格納
}
br.close();
for( i = buffers.length - 1; i >= 0 ; i-- )
System.out.println( buffers[i] );
}
catch( IOException ioe ) {
System.out.println( ioe.toString() );
}
catch( ArrayIndexOutOfBoundsException aiobe ) {
// 添字範囲逸脱の例外を処理
System.out.println( aiobe.toString() );
}
}
}
【配列のメカニズム】
ここで配列の利点欠点をはっきりさせるために,配列がメモリ上でどのような形を取っているかを説明することにしましょう。
Fig.1が,N個のT型要素を持つ配列のメモリ上の姿です。T型のデータがちょうどN個分だけ格納できるひとかたまりのメモリ
領域が一度に確保され,そこに0番目から(N-1)番目の要素がすきまなく並んでいます。
メモリ上の情報にアクセスするには,メモリ上の情報の位置,つまりアドレスを指定する必要があります。配列の場合,"同じ大きさ"
の変数(要素)が“すきまなく”が並んでいるという性質から,各要素のアドレスを簡単な計算で瞬時に求めることができます。例えば,
T型配列arrayのn番目の要素のメモリアドレスは
配列の先頭アドレス + (n × (T型データの一個一個の大きさ))
という単純な計算で得ることが可能なわけです。メモリ上へのアクセスはそのアドレスさえ分かってしまえば瞬時に実行できます。
このことから,配列の場合,どの要素へのアクセスでも可能で,しかもそのアクセスは瞬時に行われるということになります。このように,
どの要素にでも同じ程度の時間で自由にアクセスできる性質をランダムアクセス(random access)と言います。
配列のような情報を保持するためのデータ構造を,一般にコレクション(collection)とかコンテナ(container)と呼びます。コレクション
は文字通り「何かを集めたもの」を表しています。コンテナという単語はズバリ,“容器”という意味で,貨物輸送用のコンテナと同じ
単語です。Javaでは、コレクションという用語の方を主に用います。配列は,高速なランダムアクセスを提供するコレクション,というわけ
です。
【配列の性質】
ここで配列の性質についてもう少しよく考えてみましょう。まず配列の利点ですが,これは前述したように,“配列はメモリ上に要素
がきっちりと隙間なく連続してならんでいるような領域として確保される”,という性質によって生まれてきます。要素が連続して隙間
なく並んでいるおかげで,各要素のアドレスが簡単な計算で求められ,要素への高速なランダムアクセスが可能になっているわけです。
しかし,まさにその“メモリ上に要素が隙間なく連続してならんでいる”という性質が,配列を少々柔軟性を欠いたコレクションにして
しまっているのです。配列は次のような欠点を持っています。
・要素の挿入・削除の効率が悪い
・要素数が変更できない
これら柔軟性の無さを象徴する欠点は,いずれも配列の“要素がメモリ上に連続して存在している”という性質に起因しているのです。
コレクションに格納されている要素の前後関係に意味があるような場合には,要素の挿入や削除は重要になってきます。しかしながら,
配列においては要素の間に新たな要素を挿入したり,特定の要素を削除したりする作業は効率の悪いものになってしまいます。
例としてFig.3-(1)に示す6個の要素を持つ配列への要素の挿入を考えてみましょう。
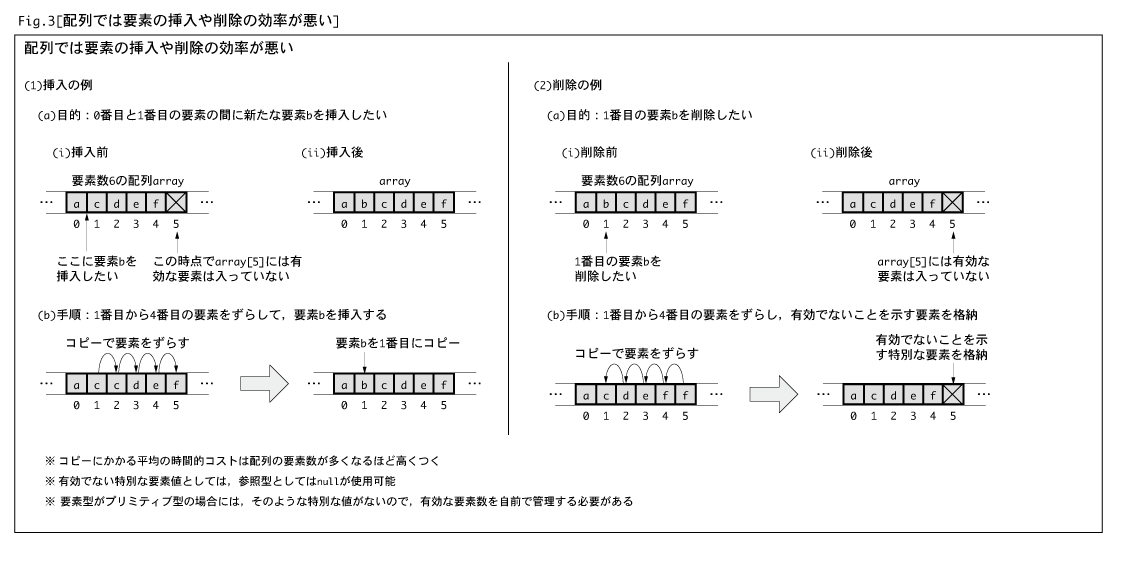
今,この配列には5つの有効な要素(a,c,d,e,f)が格納されていて,本来5番目の要素が格納されている場所には有効な要素は
格納されていないものとします。そして,0番目と1番目の要素の間に新たな要素bを格納する必要が生じたとします。すると,
配列の“要素がメモリ上に連続して存在していなければならない”という構造上,要素を挿入する前に,1番目から4番目の要素
の全てをコピーによってひとつずつ後方へずらさなければなりません(Fig.3-(1)の(b))。
このコピーにかかる時間的なコストは,配列に格納している要素数が大きくなればなるほど,高くつくことになります。削除の場合
も同様に“ずらしコピー”が必要になります(Fig.3-(2))。
ところで,Fig.3の例は実際に格納している要素,すなわち有効な要素の数(要素の挿入と削除によって増減)が,配列の要素数
と一致しない場合もあることを示しています。配列はそのランダムアクセス性から,有効でない要素に対しても簡単にアクセスで
きてしまいます。そのため,要素の全てが有効とは限らないような使い方をしているケースでは,各要素が有効であるかどうかを
判別する手段が必要になってきます。一番便利な方法は,要素自体で判別できるようにしておくことです。有効でない特別な
要素値としては,参照型のnullが使用できます。
しかし,要素型がプリミティブ型の場合には,そのような特別な値がないので,有効な要素数を自前で管理するなどして,対処
しなければなりません。
さて,Fig.3の例では有効な要素数が配列の要素数に達していなかったために,新たな要素を挿入することができました。しかし,
配列の要素全てが有効である状態で更に要素を挿入する必要が生じた場合はどうしましょう?
もちろん,一度作成した配列の大きさを自由に変えることができれば問題は解決するわけですが,実際には配列の要素数を
プログラム実行時に変更することはできません。次にこのことについて考えてみます。
6個の要素を持つ配列arrayが既に存在している場合に,更に2個の要素を格納する必要が生じた場合を例にしてみましょう。
まず,最初に確保されている要素N個の配列の領域はFig.4-(1)のようになっているわけです。このとき配列領域の前後には他
の使用中(確保済み)のメモリ領域があるかもしれないことに注意して下さい。Fig.4-(1)の例でも,配列arrayのすぐ後ろに
使用中のメモリ領域AとBがあります。
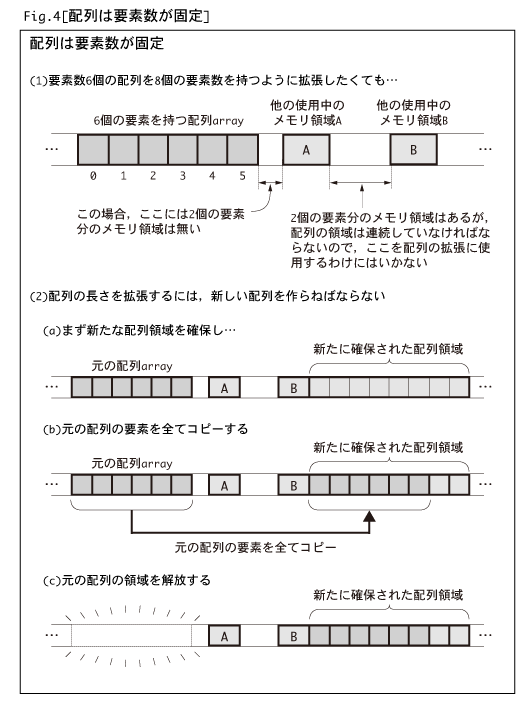
もし,拡張したい分だけの未使用領域が既存の配列の直後に有れば,運良く配列を拡張することができるかもしれませんね。
しかし,一般にメモリ領域を確保する場合は,そのメモリ上に順序よく確保されていきますので,Fig.4-(1)のように既存の配列
領域の後ろには他の目的で使用されているメモリ領域(図の例では領域A)が存在していることが多く,そのような試みはまず
失敗します。この場合,arrayの末端と使用済み領域Aの間には,2個分の要素を格納するだけの隙間はありません。
またFig.4-(1)の例では,使用済み領域Aと使用済み領域Bの間には2個分の要素を格納する領域はありますが,ここを配列
arrayの拡張に利用することはできません。なぜなら,配列は“要素がメモリ上に連続して存在していなければならない”からです。
したがって,一般的なプログラム言語では一度確保した配列の要素数(=配列領域の大きさ)は変更することができないように
なっています。もしどうしても配列の要素数をプログラム実行時に増やしたい場合には,Fig.4-(2)のように,別の配列領域を新
しく確保して元の配列の要素をコピーしなくてはなりません。このような配列の拡張の方法には
・一時的に多くのメモリ領域が必要
・要素のコピーに時間がかかる
という問題があります。Fig.4-(2)の(a)と(b)を見ればわかりますが,コピーの作業を行うためには元の配列と新しい配列,
すなわち元の配列の2倍以上のメモリ領域が必要になります。そしてそのコピーにかかる時間は,要素の大きさと要素数が
大きくなるにつれて長くなってしまうわけです。
【ベクタ】
しかし,プログラム実行時に大きさが変えられる配列は,配列を拡張するときに生じるメモリ容量とコピー時間のオーバヘッドなど
の問題点が有ったとしても用途によっては十分魅力的ではあります。実際,Javaではベクタ(vector)と呼ばれるクラスが用意
されており,動的に大きさが変えられる配列として使えるようになっています。仕組みとしては,ベクタオブジェクトが内部的に配列
を保持していて,その配列の前半部分に有効な要素が詰められており,配列に格納できる要素数(容量)と有効な要素の数を管理
するようになっています(Fig.5)。Javaでは,容量をcapacity,有効な要素の数をsizeと呼んでいます。
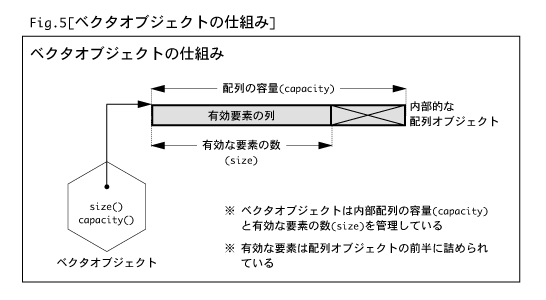
この内部配列の容量は明示的に指定しても変えられるようになっていますが,ベクタクラスの便利なところは,要素の挿入時に配列の
容量が足らなくなった場合に,自動的に配列領域を拡張してくれるという点です。ではJavaのベクタクラスから説明していきましょう。
【Javaのベクタクラス】
JavaのVectorクラス(パッケージはjava.util)は,Object型変数を要素に持つ高機能な配列として機能します。Table 1 に Vector
の主な機能を示します。
(Vectorの完全な説明書はこちら)

※addElementメソッドは,実引数に指定されたオブジェクトをObject型としてVectorの有効要素列の最後に追加し,サイズを1増やす。
※addメソッドはCollectionインタフェイスから継承したメソッドで,addElementメソッド同様に実引数に指定されたオブジェクトを
Object型としてVectorの有効要素列の最後に追加し,サイズを1増やす。Vectorの場合,このaddメソッドは常にtrueを返す。
Vectorの要素の型はObject型なので,クラス型のオブジェクトならばなんでも格納することができます。また,配列と言っても所詮
はクラス型のオブジェクトですから,[ ]演算子を使った要素へのアクセスはできません。かわりに,添字整数を引数に持つメソッド
elementAtやsetElementAtによって要素へアクセスします。
それでは,Vectorの使用例を見てみましょう。List 2はVectorオブジェクトを利用して List 1を書き直したものです。9行目で
Vectorオブジェクトbuffersを宣言しています。コンストラクタの引数にはVectorの配列の大きさ,すなわちコレクションとしての
容量(capacity)が指定されています。List 2では,この値を50に設定しています。つまり,このままでは配列の大きさは少なすぎる
わけです。よって51個めの要素を挿入するところで,配列の自動的な拡張が起こることになります。
その要素への挿入ですが,List 2では15行目のメソッドaddElementで行っています。このaddElementはVectorオブジェクトの
内部配列の有効要素の列の最後に,指定された要素を追加します。このような有効要素の列の最後に新しい要素をつけ加えるという
挿入の仕方は,Fig.3-(1)で問題にした“ずらしコピー”の必要がないので高速に行うことができます。ですから,挿入する要素の順番
が特に問題にならない場合や,要素を順次挿入していくだけの場合には,このような有効要素列の末尾への追加手続きを利用する
べきです。そして18〜19行目のfor文で,前述のメソッドelementAtを使ってベクタの要素の各文字列を添字つきで読み出し,表示
しています。
List 2を実行してみると,ちゃんとList 2と同じように表示され,Vectorオブジェクトの内部配列が自動的に拡張されていることが
わかります。
List 2 Reverse3.java データファイル weapon.csv
import java.io.*;
import java.util.*; // for Vector
public class Reverse3 {
public static void main( String args[] ) {
try {
final int arrayN = 50;
// ベクタオブジェクトbuffers(初期容量50)
Vector buffers = new Vector( arrayN );
String str;
BufferedReader br = new BufferedReader
( new FileReader( "weapon.csv" ) );
while( ( str = br.readLine() ) != null ) {
// ベクタにデータを挿入
buffers.addElement( str );
}
br.close();
for( int i = buffers.size() - 1; i >= 0 ; i-- )
System.out.println( buffers.elementAt( i ) );
}
catch( IOException ioe ) {
System.out.println( ioe.toString() );
}
catch( ArrayIndexOutOfBoundsException aiobe ) {
// 添字範囲逸脱の例外を処理
System.out.println( aiobe.toString() );
}
}
}
実は,Vector型オブジェクトは,次回解説する「スレッド」に関してある特徴を持っています。それは,複数のスレッド
から同時に利用されても安全である(スレッドセーフと言う)ように定義されています。詳しくは次回説明します。Vectorは
スレッドセーフである分,処理は若干低速になってしまっています。
Java には,Vectorと同じ様に使える高機能配列として ArrayList クラスが用意されています。ArrayList はスレッドセーフ
ではない分,高速で,現在では Vector より ArrayList を使う方が主流になっています。
次は, Vectorの弱点のいくつかを解決できるプリミティブラッパークラス,ジェネリッククラス,ジェネリッククラス版
Vector<E>,ArrayList<E> について紹介します。